To see posts by date, check out the archives
Netbooks are dead, but the Chuwi Minibook X scratches the same itch.
The Minibook X is a 10.5″ x86_64 sub-ultrabook with 16GB RAM, a 512GB NVMe drive, and only one majorly annyoing Linux quirk.
I needed a knock-around laptop, so I bought myself a Minibook for my birthday last year. The more I tote it around, the more fun I’m having with this ridiculous little computer.

Quick specs
Much like the netbooks of yore, the Minibook is a budget machine. But it’s 2026, so even budget machines pack more oomph than I need from a utility laptop.
- CPU 4-core/4-thread 3.6GHz Intel N150 Twin Lake
- 16 GB RAM – LPDDR5-6400 – soldered 😿
- 512GB NVMe – upgradable
- 10.51” IPS 2K 16:10 screen
- 28.88Wh Li-Ion battery
- Weight: 911g
- Ports: 2×USB-C (1×PD charging)
- Cost: $350

One oddity is that the Minibook comes bundled with a 12V/2A USB-C charger. I chucked the charger; I worried I’d fry some 5V SoC someday. The Minibook works fine with a PD charger.

I’d assume the 12V charger was a cost-saving choice, but it also creates some weird possibilities for DC/off-grid setups.
Linux and weirdness: sideways panels and kernel parameters
The fediverse told me that Minibook runs Linux “boringly well,” which was almost true.
I tried Debian, then jumped to NixOS for kicks.
What works:
- Camera/Microphone/Speakers
- Touchscreen
- Sleep/Suspend
- Hibernate
- Keyboard backlight
- USB-C HDMI
- Bluetooth (non-free blobs – Intel)
- Wi-Fi 6 (non-free blobs – Intel)
But on first boot, the screen orientation is 270° clockwise:
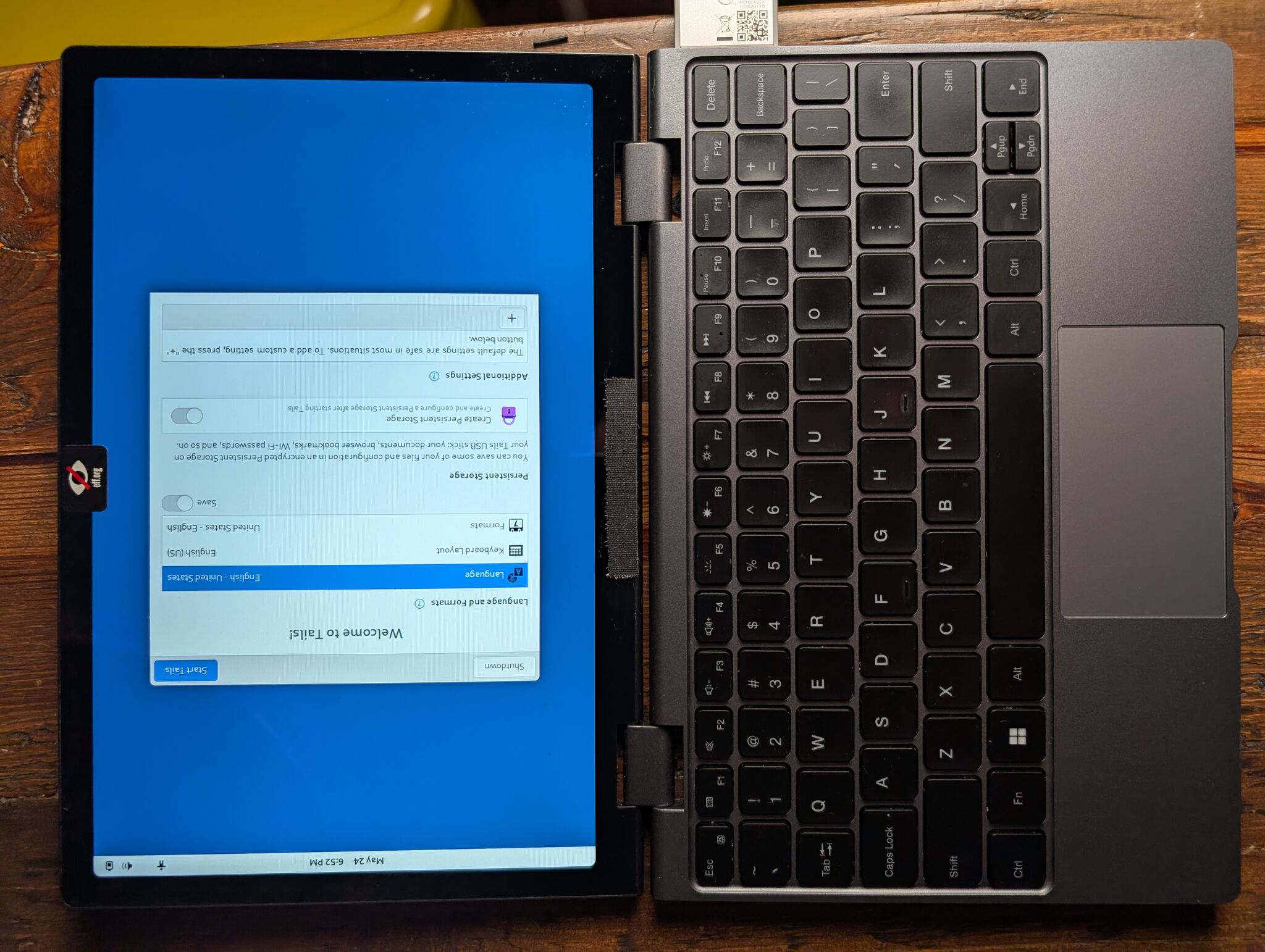
The Chuwi’s screen is a panel from a cheap tablet; the screen rotation issue is a hardware problem (the screen is mounted sideways). To fix the screen’s rotation, I had to tweak screen orientation at every software layer. Fixing this problem was a journey:
- Bootloader – Switched from
systemd-boottogrub, carrying some unmerged GRUB rotation patches on top. - Initrd – Tell the Intel display driver about the panel orientation
via a kernel parameter, and force the Intel driver to load in the
initramfs. On NixOS:
boot.kernelParams = ["video=DSI-1:panel_orientation=right_side_up"];andboot.initrd.kernelModules = ["i915"];(see Kernel docs for modedb default video mode support) - Desktop environment – For X11, good ole
xrandr --output DSI-1 --rotate right. Wayland picked this up from the DRM connector. This one was easy. - Framebuffer – Ensure all TTYs have the proper orientation by adding
fbcon=rotate:1to kernel parametersboot.kernelParams = ["fbcon=rotate:1"];(see Kernel docs for framebuffer console boot options)
Behold, the final result in all its glory:
mainframed/Hackers-PlymouthSize, weight, and build
This computer is mind-bogglingly small. The build is sturdy and totable; it’ll hold up to a backpack jostling.

The laptop’s case is MacBook-esque: aluminum and good-looking. The MacBook Air’s dimensions dwarf the Chuwi’s, but the two laptops are about the same thickness.


A notebook that weighs more than a kilo is simply not a good thing
The Minibook weighs in just shy of a kilo at 912 grams.

Perf, thermals, and power
tl;dr: you get what you pay for. But battery life and cooling are better than I’d have guessed.
The Minibook X was never going to compile the Linux kernel in record time. But the performance matches the specs, it stays cool, and it has enough battery life to run a movie marathon.
Numbers:
- Geekbench6 (a fun side-quest to get running on NixOS), better than I
expected.
- Single-core: 1295
- Multi-core: 3332
- Wi-Fi 6 speed: 424 Mbps, more than enough to stream a 4K movie.
- Power
- Idle: 3.8W
- During benchmark: ~15W
Battery: When I left the 1995 classic film “Hackers” looping in VLC, the battery lasted about 6 hours.
Heat: Running stress-ng for 10 minutes, the hottest part
of the laptop chassis remained below 90°F (32°C):

What I dislike
There’s so much to dislike about this laptop:
- Screen is terrible – 2K? 50Hz refresh rate? Why!?
- Keyboard is terrible – it only registers keystrokes when you hit the exact center of each key.
- Touchpad is terrible – It’s a diving board-style, without physical buttons.
- Sound is meh – I can hear the tinny laptop speaker fine, but it’s underwhelming. I’ve never tried tweaking it in Pipewire, though; it’s possible it could be better.
But “terrible” is in comparison to the nicest modern laptops in existence. Everything I listed here works fine. I’m honestly blown away when I tune my expectations to the sub-$400 laptop range.
Verdict
In The Death and Life of Great American Cities, Jane Jacobs wrote, “new ideas require old buildings”: cheap spaces let people try risky ideas.
The Chuwi Minibook X is an old building.
I can brick the Minibook and have a normal Monday on my serious work laptop. Nothing has to work, which makes it perfect to try out new Linux desktop stuff:
- NixOS – I’ve been using Debian for 15 years+, figured I’d try joining the NixOS cult for a while.
- RiverWM – I’m on a quest to find the Wayland version of XMonad; River is pretty close.
- KDE Plasma – I’ve used a tiling window manager for over a decade. What’s it like to use a desktop that Just Works™?
- Steam – Never been much into games, but I decided to give Steam a try since, well, why not?
Cheap, weird computers like the Chuwi make it safe to play. And playing with computers is still fun.
Hackers are pwning packages at an exhausting clip, and GitHub Actions features in every postmortem.
In late February, a hackerbot AI1 yoinked the release key for a single project. Within a month, fifty-ish other projects had cred stealers. Each infected repo swiped credentials for the next.
This spate of supply-chain hacks started from a GitHub Actions trap; a simple, bad default with a five-year-old proposed fix.
GitHub Actions and consequences

Trivy is an open-source security scanner. But if you used Trivy in late March, you had a bad time.
On March 19th, hackers pushed a version of Trivy that tried to smuggle secrets from anywhere it ran. Trivy cited a “misconfiguration” in their continuous integration (CI) system, GitHub Actions.
But the exploit was less a misconfiguration and more a GitHub Actions trap.
Here’s a simplified version of how Trivy got pwnd2:
# INSECURE. DO NOT USE.
on:
pull_request_target
jobs:
check:
steps:
- uses: action/checkout@deadbeefdeadbeefdeadbeefdeadbeefdeadbeef
with:
ref: refs/pull/${{ github.event.pull_request.number }}/merge
- uses: ./.github/actions/setup-go
- uses: some/go-static-analysis@c0ffeec0ffeec0ffeec0ffeec0ffeec0ffeec0ffAt first glance, this code looks fine:
- No secrets referenced.
- Third-party actions pinned to an immutable hash.
- Check out a pull request. Perform some static analysis.
But this code is a verbatim antipattern from a 2021 GitHub blog post titled “preventing pwn requests”:
if the
pull_request_targetworkflow only […] runs untrusted code but doesn’t reference any secrets, is it still vulnerable?Yes it is
The problem is pull_request_target:
pull_request_target– plunks a nice, juicyGITHUB_TOKENinto the environment.actions/checkout– takes an optional parameterpersist-credentials, which removes secrets if set tofalse. But the default for the parameter istrue.
Setting the persist-credentials parameter to
false has been an open issue in GitHub Actions since
2021.
Your $HOME is a crime scene
Once hackers had Trivy’s keys, they published a new version of Trivy to steal more keys.
LiteLLM used Trivy in their CI. The same CI they used to publish code to PyPI, the Python software registry. When LiteLLM’s CI ran the compromised Trivy, hackers nabbed their publishing key.
And on March 24th, when Callum McMahon fired up his IDE, his MacBook froze. And that’s how he discovered the LiteLLM hijack.
McMahon’s MacBook was flailing at bad code that hackers snuck into LiteLLM. And the bad code trying to steal credentials:
~/.netrc~/.aws/credentials~/.config/gcloud~/.config/gh~/.azure~/.docker/config.json~/.npmrc~/.git-credentials~/.kube/
Files that are typically strewn around $HOME
directories, full of tokens and keys, often unencrypted.
AI and the supply chain doom spiral
We’ve dealt with problems like unencrypted credentials, unpinned dependencies, and CI footguns forever.
But AI has accelerated everything, including repeating security mistakes.
On the day of the Trivy compromise, I asked Claude, “how do I scan docker registry images for security vulnerabilities?”
The reply, in part:
CI/CD Integration Example (GitHub Actions with Trivy)
- name: Scan image for vulnerabilities
uses: aquasecurity/trivy-action@masterBroken in two ways:
- Unpinned references –
masteris a reference that changes all the time. If hackers zombify the repo, I’d be the first victim. - Active vulnerability – No mention whatsoever of the CVE posted that day. I never asked, so Claude never checked.
Meanwhile, Vercel’s CEO has attributed his company’s recent data breach to a hacker that was “accelerated by AI.” And Anthropic’s latest hype tour includes briefing the US Federal Reserve Chair about vulnerabilities unearthed by their frontier model.
Bad guys with LLMs get superpowers. Good guys with LLMs fall prey to mid-2010’s CI problems.
And the same tool that can root out 27-year-old
security problems in OpenBSD, will still tell you to pin your GitHub
actions to @master.
Or somone calling themselves
hackerbot-claw, at any rate.↩︎My GitHub Actions example is a simpler verison of the action removed in aquasecurity/trivy #10259.↩︎
If Git had a nemesis, it’d be large files.
Large files bloat Git’s storage, slow down git clone,
and wreak havoc on Git forges.
In 2015, GitHub released Git LFS—a Git extension that hacked around problems with large files. But Git LFS added new complications and storage costs.
Meanwhile, the Git project has been quietly working on large files. And while LFS ain’t dead yet, the latest Git release shows the path towards a future where LFS is, finally, obsolete.
What you can do today: replace Git LFS with Git partial clone
Git LFS works by storing large files outside your repo.
When you clone a project via LFS, you get the repo’s history and small files, but skip large files. Instead, Git LFS downloads only the large files you need for your working copy.
In 2017, the Git project introduced partial clones that provide the same benefits as Git LFS:
Partial clone allows us to avoid downloading [large binary assets] in advance during clone and fetch operations and thereby reduce download times and disk usage.
– Partial Clone Design Notes, git-scm.com
Git’s partial clone and LFS both make for:
- Small checkouts – On clone, you get the latest copy of big files instead of every copy.
- Fast clones – Because you avoid downloading large files, each clone is fast.
- Quick setup – Unlike shallow clones, you get the entire history of the project—you can get to work right away.
What is a partial clone?
A Git partial clone is a clone with a --filter.
For example, to avoid downloading files bigger than 100KB, you’d use:
git clone --filter='blobs:size=100k' <repo>Later, Git will lazily download any files over 100KB you need for your checkout.
By default, if I git clone a repo with many revisions of
a noisome 25 MB PNG file, then cloning is slow and the checkout is
obnoxiously large:
$ time git clone https://github.com/thcipriani/noise-over-git
Cloning into '/tmp/noise-over-git'...
...
Receiving objects: 100% (153/153), 1.19 GiB
real 3m49.052sAlmost four minutes to check out a single 25MB file!
$ du --max-depth=0 --human-readable noise-over-git/.
1.3G noise-over-git/.
$ ^ 🤬And 50 revisions of that single 25MB file eat 1.3GB of space.
But a partial clone side-steps these problems:
$ git config --global alias.pclone 'clone --filter=blob:limit=100k'
$ time git pclone https://github.com/thcipriani/noise-over-git
Cloning into '/tmp/noise-over-git'...
...
Receiving objects: 100% (1/1), 24.03 MiB
real 0m6.132s
$ du --max-depth=0 --human-readable noise-over-git/.
49M noise-over-git/
$ ^ 😻 (the same size as a git lfs checkout)My filter made cloning 97% faster (3m 49s → 6s), and it reduced my checkout size by 96% (1.3GB → 49M)!
But there are still some caveats here.
If you run a command that needs data you filtered out, Git will need
to make a trip to the server to get it. So, commands like
git diff, git blame, and
git checkout will require a trip to your Git host to
run.
But, for large files, this is the same behavior as Git LFS.
Plus, I can’t remember the last time I ran git blame on
a PNG 🙃.
Why go to the trouble? What’s wrong with Git LFS?
Git LFS foists Git’s problems with large files onto users.
And the problems are significant:
- 🖕 High vendor lock-in – When GitHub wrote Git LFS, the other large file systems—Git Fat, Git Annex, and Git Media—were agnostic about the server-side. But GitHub locked users to their proprietary server implementation and charged folks to use it.1
- 💸 Costly – GitHub won because it let users host repositories for free. But Git LFS started as a paid product. Nowadays, there’s a free tier, but you’re dependent on the whims of GitHub to set pricing. Today, a 50GB repo on GitHub will cost $40/year for storage. In contrast, storing 50GB on Amazon’s S3 standard storage is $13/year.
- 😰 Hard to undo – Once you’ve moved to Git LFS, it’s impossible to undo the move without rewriting history.
- 🌀 Ongoing set-up costs – All your collaborators need to install Git LFS. Without Git LFS installed, your collaborators will get confusing, metadata-filled text files instead of the large files they expect.
The future: Git large object promisors
Large files create problems for Git forges, too.
GitHub and GitLab put limits on file size2 because big files cost more money to host. Git LFS keeps server-side costs low by offloading large files to CDNs.
But the Git project has a new solution.
Earlier this year, Git merged a new feature: large object promisers. Large object promisors aim to provide the same server-side benefits as LFS, minus the hassle to users.
This effort aims to especially improve things on the server side, and especially for large blobs that are already compressed in a binary format.
This effort aims to provide an alternative to Git LFS
– Large Object Promisors, git-scm.com
What is a large object promisor?
Large object promisors are special Git remotes that only house large files.
In the bright, shiny future, large object promisors will work like this:
- You push a large file to your Git host.
- In the background, your Git host offloads that large file to a large object promisor.
- When you clone, the Git host tells your Git client about the promisor.
- Your client will clone from the Git host, and automagically nab large files from the promisor remote.
But we’re still a ways off from that bright, shiny future.
Git large object promisors are still a work in progress. Pieces of large object promisors merged to Git in March of 2025. But there’s more to do and open questions yet to answer.
And so, for today, you’re stuck with Git LFS for giant files. But once large object promisors see broad adoption, maybe GitHub will let you push files bigger than 100MB.
The future of large files in Git is Git.
The Git project is thinking hard about large files, so you don’t have to.
Today, we’re stuck with Git LFS.
But soon, the only obstacle for large files in Git will be your half-remembered, ominous hunch that it’s a bad idea to stow your MP3 library in Git.
Edited by Refactoring English
Later, other Git forges made their own LFS servers. Today, you can push to multiple Git forges or use an LFS transfer agent, but all this makes set up harder for contributors. You’re pretty much locked-in unless you put in extra effort to get unlocked.↩︎
File size limits: 100MB for GitHub, 100MB for GitLab.com↩︎
People should try to compare the quality of the kernel git logs with some other projects, and cry themselves to sleep.
– Linus Torvalds
I’ll never remember your project’s commit guidelines.
Every project insists on something different:
- Conventional commits
- Problem/Solution format
- Gitmoji
- The twisty maze of trailers in the Linux Kernel
But git commit templates help. Commit templates provide a scaffold for commit messages, offering documentation where you need it: inside the editor where you’re writing your commit message.
What is a git commit template?
When you type git commit, git pops open your text
editor1. Git can pre-fill your editor with a
commit template—it’s like a form you fill out.
Creating a commit template is simple.
- Create a plaintext file – mine lives at
~/.config/git/message.txt - Tell git to use it:
git config --global \
commit.template '~/.config/git/message.txt'My default template packs everything I know about writing a commit.
Project-specific templates with IncludeIf
The real magic of commit templates is you can have different templates for each project.
Different projects can use different templates with git’s
includeIf configuration setting.2
Large projects, such as the Linux kernel, git, and MediaWiki, have their own commit guidelines.
For Wikimedia work, I stow git repos in
~/Projects/Wikimedia and at the bottom of my global git
config (~/.config/git/config) I have:
[includeIf "gitdir:~/Projects/Wikimedia/**"]
path = ~/.config/git/config.wikimediaIn config.wikimedia, I point to my Wikimedia-specific
commit template. I also override other git config settings like my
user.email or core.hooksPath.
An example: my global template
My default commit template contains three sections:
- Subject – 50 characters or less, capitalized, no end punctuation.
- Body – Wrap at 72 characters with a blank line separating it from the subject.
- Trailers – Standard formats with a blank line separating them from the body.
In each section, I added pointers for both format3 and content.
For the header, the guidance is quick:
# 50ch. wide ----------------------------- SUBJECT
# |
# "If applied, this commit will..." |
# |
# Change / Add / Fix |
# Remove / Update / Document |
# |
# ------- ↓ LEAVE BLANK LINE ↓ ---------- /SUBJECT
For the body, I remind myself to answer basic questions:
# 72ch. wide ------------------------------------------------------ BODY
# |
# - Why should this change be made? |
# - What problem are you solving? |
# - Why this solution? |
# - What's wrong with the current code? |
# - Are there other ways to do it? |
# - How can the reviewer confirm it works? |
# |And that’s it, except for git trailers.
The twisty maze of git trailers
My template has a section for trailers used by the projects I work on.
# TRAILERS |
# -------- |
# (optional) Uncomment as needed. |
# Leave a blank line before the trailers. |
# |
# Bug: #xxxx
# Acked-by: Example User <user@example.com>
# Cc: Example User <user@example.com>
# Co-Authored-by: Example User <user@example.com>
# Requested-by: Example User <user@example.com>
# Reported-by: Example User <user@example.com>
# Reviewed-by: Example User <user@example.com>
# Suggested-by: Example User <user@example.com>
# Tested-by: Example User <user@example.com>
# Thanks: Example User <user@example.com>These trailers serve as useful breadcrumbs of documentation. Git can parse them using standard commands.
For example, if I wanted a tab-separated list of commits and their
related tasks, I could find Bug trailers using
git log:
$ TAB=%x09
$ BUG_TRAILER='%(trailers:key=Bug,valueonly=true,separator=%x2C )'
$ SHORT_HASH=%h
$ SUBJ=%s
$ FORMAT="${SHORT_HASH}${TAB}${BUG_TRAILER}${TAB}${SUBJ}"
$ git log --topo-order --no-merges \
--format="$FORMAT"
d2b09deb12f T359762 Rewrite Kurdish (ku) Latin to Arabic converter
28123a6a262 T332865 tests: Remove non-static fallback in HookRunnerTestBase
4e919a307a4 T328919 tests: Remove unused argument from data provider in PageUpdaterTest
bedd0f685f9 objectcache: Improve `RESTBagOStuff::handleError()`
2182a0c4490 T393219 tests: Remove two data provider in RestStructureTestStop remembering commit message guidelines
Git commit templates free your brain from remembering what to write, allowing you to focus on the story you need to tell.
Save your brain for what it’s good at.
[The] Linux kernel uses GPLv2, and if you distribute GPLv2 code, you have to provide a copy of the source (and modifications) once someone asks for it. And now I’m asking nicely for you to do so 🙂
– Joga, bbs.onyx-international.com

In January, I bought a Boox Go 10.3—a 10.3-inch, 300-ppi, e-ink Android tablet.
After two months, I use the Boox daily—it’s replaced my planner, notebook, countless PDF print-offs, and the good parts of my phone.
But Boox’s parent company, Onyx, is sketchy.
I’m conflicted. The Boox Go is a beautiful, capable tablet that I use every day, but I recommend avoiding as long as Onyx continues to disregard the rights of its users.
How I’m using my Boox

Each morning, I plop down in front of my MagicHold laptop stand and journal on my Boox with Obsidian.
I use Syncthing to back up my planner and sync my Zotero library between my Boox and laptop.
In the evening, I review my PDF planner and plot for tomorrow.
I use these apps:
- Obsidian – a markdown editor that syncs between all my devices with no fuss for $8/mo.
- Syncthing – I love Syncthing—it’s an encrypted, continuous file sync-er without a centralized server.
- Meditation apps1 – Guided meditation away from the blue light glow of my phone or computer is better.
Before buying the Boox, I considered a reMarkable.
The reMarkable Paper Pro has a beautiful color screen with a frontlight, a nice pen, and a “type folio,” plus it’s certified by the Calm Tech Institute.
But the reMarkable is a distraction-free e-ink tablet. Meanwhile, I need distraction-lite.
What I like
- Calm(ish) technology – The Boox is an intentional device. Browsing the internet, reading emails, and watching videos is hard, but that’s good.
- Apps – Google Play works out of the box. I can install F-Droid and change my launcher without difficulty.
- Split screen – The built-in launcher has a split screen feature. I use it to open a PDF side-by-side with a notes doc.
- Reading – The screen is a 300ppi Carta 1200, making text crisp and clear.
What I dislike

- Typing – Typing latency is noticeable.
- At Boox’s highest refresh rate, after hitting a key, text takes between 150ms to 275ms to appear.
- I can still type, though it’s distracting at times.

- Accessories
- Pen – The default pen looks like a child’s whiteboard marker and feels cheap. I replaced it with the Kindle Scribe Premium pen, and the writing experience is vastly improved.
- Cover – It’s impossible to find a nice cover. I’m using a $15 cover that I’m encasing in stickers.
- Tool switching – Swapping between apps is slow and clunky. I blame Android and the current limitations of e-ink more than Boox.
- No frontlight – The Boox’s lack of frontlight prevents me from reading more with it. I knew this when I bought my Boox, but devices with frontlights seem to make other compromises.
Onyx
The Chinese company behind Boox, Onyx International, Inc., runs the servers where the Boox routes telemetry. I block this traffic with Pi-Hole2.

I inspected this traffic via Mitm proxy—most traffic was benign, though I never opted into sending any telemetry (nor am I logged in to a Boox account). But it’s also an Android device, so it’s feeding telemetry into Google’s gaping maw, too.
Worse, Onyx is flouting the terms of the GNU Public License, declining to release Linux kernel modifications to users. This is anathema to me—GPL violations are tantamount to theft.
Onyx’s disregard for user rights makes me regret buying the Boox.
Verdict
I’ll continue to use the Boox and feel bad about it. I hope my digging in this post will help the next person.
Unfortunately, the e-ink tablet market is too niche to support the kind of solarpunk future I’d always imagined.
But there’s an opportunity for an open, Linux-based tablet to dominate e-ink. Linux is playing catch-up on phones with PostmarketOS. Meanwhile, the best e-ink tablets have to offer are old, unupdateable versions of Android, like the OS on the Boox.
In the future, I’d love to pay a license- and privacy-respecting company for beautiful, calm technology and recommend their product to everyone. But today is not the future.
I go back and forth between “Waking Up” and “Calm”↩︎